In the world of digital experimentation, a frustrating pattern emerges: most A/B tests fail. While tools have made it easier than ever to run tests, understanding why they fail - and how to prevent these failures - remains a significant challenge. This guide focuses on the hidden psychological factors that doom most tests and the practical methods to overcome them.
Most A/B tests fail for three primary psychological reasons, not technical ones:
Many organizations abandon testing programs after seeing consistent negative results. This reaction is understandable but misguided. When tests appear to fail because of these psychological factors, organizations face several significant consequences:
The true cost isn't just the failed tests themselves, but the organizational momentum and potential improvements that never materialize.
Conventional A/B testing methodology often overlooks these psychological factors. Tests are evaluated too early, before users adjust to changes. Return visitor behavior is misinterpreted as genuine preference. Short-term negative reactions are confused with long-term user preferences. And test segments aren't properly analyzed to understand the source of negative results.
This guide provides a framework for conducting tests that account for these psychological barriers, covering methods to separate genuine user preference from change aversion, techniques for proper test segmentation and analysis, and ways to identify true test failures versus psychological resistance.
When examining test results, distinguishing between genuine design problems and temporary user adaptation periods is crucial. A true failure indicates fundamental issues with your solution's value proposition or usability. Temporary resistance, however, simply reflects users adjusting to change.
Before concluding a design doesn't work, consider these diagnostic questions:
Implementation issues often masquerade as test failures. Verify that all test variations are being served as intended and that the test experience is consistent across the user journey.
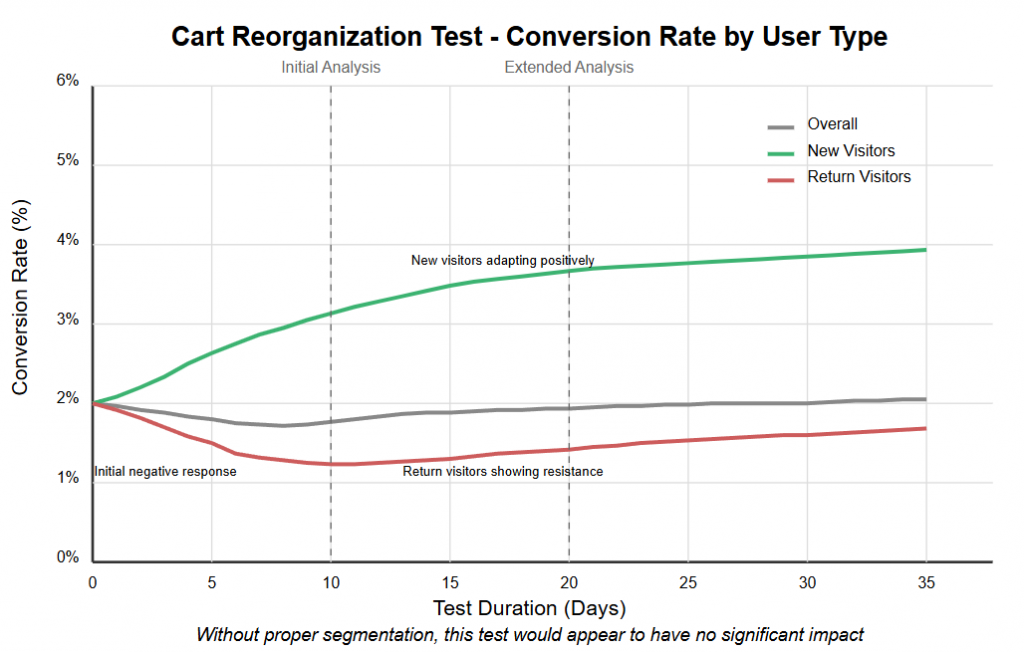
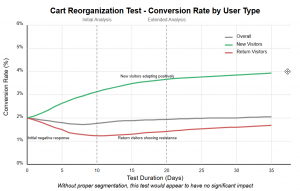
Let's examine a real-world example that perfectly illustrates how return visitor behavior can mask genuine test success. In this cart reorganization test, the overall conversion rate showed almost no improvement—hovering around a mere 0.1% lift by the end of the test. By traditional standards, this test would be considered a failure and abandoned.
However, when we segment the data between new and returning visitors, a dramatically different story emerges. New visitors showed significant improvement, with conversion rates steadily climbing to a 3.8% increase by test completion. Meanwhile, returning visitors exhibited classic resistance behavior, with conversion rates declining by 1.9%.
This pattern is consistent with the psychological principles we've discussed. New visitors have no preconceived expectations about your cart experience, so they respond to the inherent usability of your new design. Returning visitors, however, experience disruption to their established mental models, creating temporary friction that manifests as decreased conversion.
Had this test been analyzed without proper segmentation, a valuable optimization opportunity would have been missed. By recognizing the pattern for what it is—new visitor improvement counterbalanced by return visitor resistance—you can make a more informed implementation decision. In this case, the appropriate action might be to gradually roll out the change, perhaps showing returning visitors an intermediary design or providing guidance about the new cart experience.
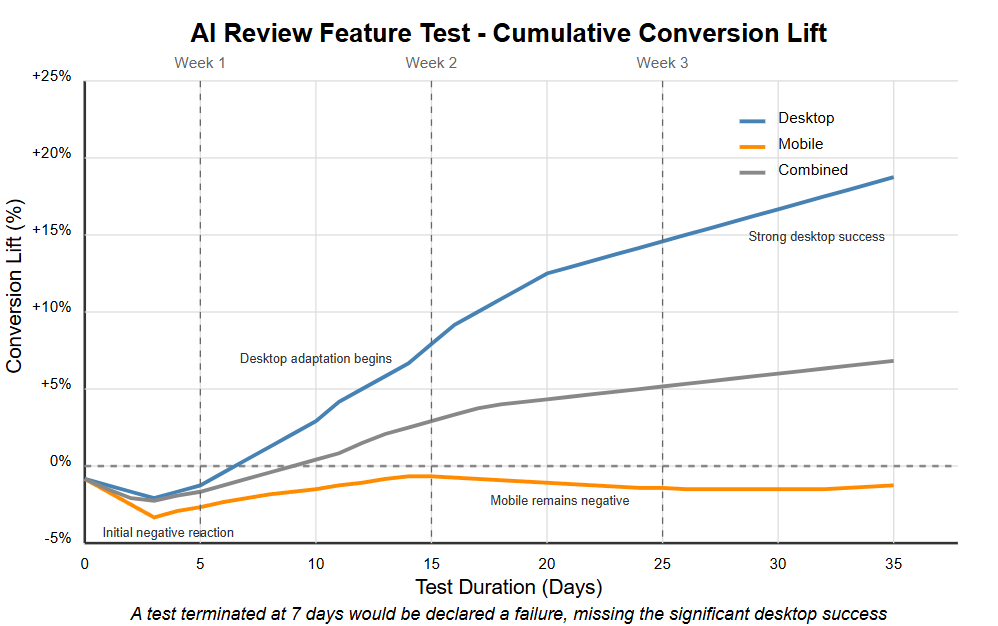
Test duration is perhaps the most critical factor in preventing false negatives. When an AI review feature was initially implemented, both desktop and mobile users showed negative reactions—a common response to novel interfaces. After just seven days, the combined test showed a 1.5% decrease in conversion rate. Many organizations would terminate the test at this point, declaring it a failure.
However, by extending the test to its full planned duration, a remarkable pattern emerged. Desktop users began adapting to the new feature around day 10, and by day 20, they showed a dramatic 15% improvement in conversion rates. Mobile users, facing greater interface constraints and different usage patterns, continued to respond negatively throughout the test period.
This example illustrates three critical insights about test duration: adaptation periods vary dramatically across user segments and devices; early negative results often reverse as users adjust to new experiences; and device-specific patterns require proper segmentation and potentially different solutions.
Had this test been terminated after the initial negative period, the substantial desktop improvement would never have been discovered. Instead, by running the full test duration, the organization gained valuable insights: implement the feature for desktop users, and either modify the approach for mobile or maintain the original experience on those devices.
User adaptation doesn't follow a predetermined timeline—it varies based on feature complexity, frequency of user visits, and the magnitude of change. This is why predetermined test durations based solely on achieving statistical significance can be dangerous. True understanding requires patience and a commitment to observing the complete adaptation cycle.
The Test Window is a systematic approach to ensure accurate test results by respecting natural user behavior and accounting for psychological adaptation periods:
Implementing the Test Window methodology requires a testing platform with robust segmentation and targeting capabilities. Look for essential features when selecting your A/B testing infrastructure: advanced visitor segmentation, duration flexibility, and robust analytics integration.
Your testing platform should allow targeting specific visitor types, offer flexible conditions based on behavior patterns, and impose no artificial constraints on test timeframes. It should also connect seamlessly to your analytics platform with custom event tracking capabilities and data visualization that reveals adaptation patterns.
Nantu, ConversionTeam's free open-source A/B testing tool, offers these capabilities without the usage fees or visitor limits common in commercial platforms. This makes it particularly well-suited for the Test Window approach, as tests can run as long as needed without incurring additional costs.
Other testing platforms can certainly implement the Test Window methodology, but carefully evaluate their segmentation capabilities and pricing models, as per-visitor fees can create disincentives for running tests through complete adaptation periods.
One of the most valuable lessons from extensive testing programs is that concepts often require multiple iterations to reach their full potential. Consider three successive tests of strikethrough pricing implemented across different parts of the user journey.
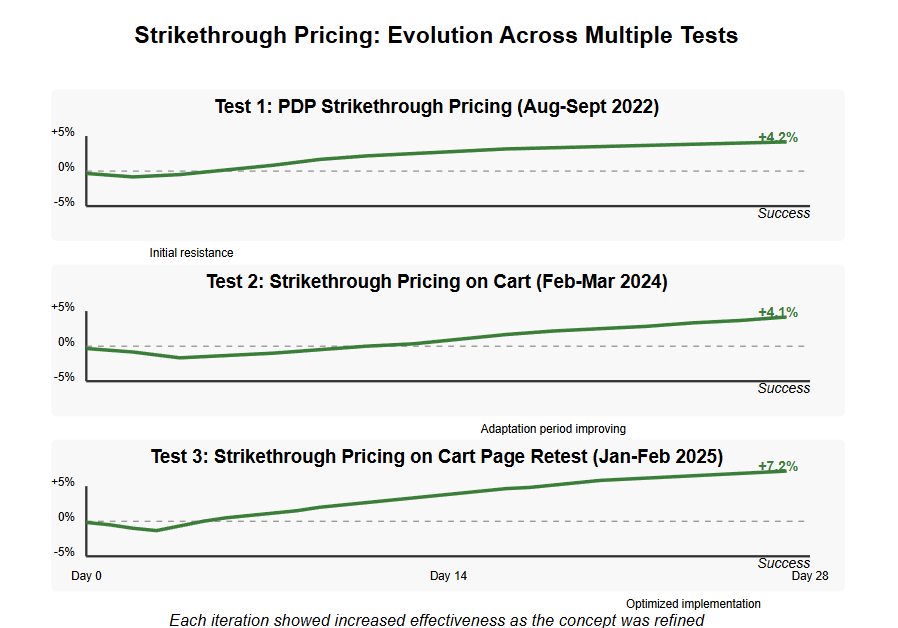
The first test introduced strikethrough pricing on product detail pages. After a brief period of user adaptation, it produced a modest but significant 4.2% conversion lift. This success prompted exploration of the same concept in the cart environment.
In the second iteration, strikethrough pricing was applied to the cart page. Initially, the change created more pronounced user resistance—with a deeper initial dip in conversion rate. This makes sense psychologically; users are further along in their purchase journey at the cart stage and more sensitive to changes in expected pricing information. However, after the adaptation period, this test also succeeded with a 4.1% improvement.
Most organizations would stop here, satisfied with two successful implementations. However, the testing team recognized an opportunity for further refinement. The third test incorporated learnings from both previous implementations, optimizing the visual design and messaging of the strikethrough pricing in the cart. The result was an impressive 7.2% conversion improvement—nearly double the impact of the earlier iterations.
This case illustrates several important principles for overcoming test "failure": conceptual persistence across multiple tests allows ideas to evolve and improve; context matters when implementing similar concepts in different parts of the user journey; iterative refinement based on user response patterns increases effectiveness over time; and patient observation of adaptation periods prevents premature rejection of valuable concepts.
Understanding the psychology of A/B testing is just the beginning. Implementing these insights requires a systematic approach supported by appropriate tools and expertise. For organizations looking to elevate their testing programs, use testing tools like Nantu that allow easy implementation of the test window methodology, develop testing protocols that account for psychological factors, and build organizational patience for true adaptation periods rather than rushing to judgment on test results.
When internal resources are limited, explore partnership with experienced optimization specialists like a dedicated CRO agency. For organizations seeking deeper support, ConversionTeam offers comprehensive services through their Hitlist CRO Audit and Iterate A/B Testing Program.
By integrating psychological awareness into your testing approach, you can transform "failed" tests into valuable optimization opportunities, ultimately creating digital experiences that truly resonate with users - once they've had time to adapt.
